How a Browser Works: A Beginner-Friendly Guide to Browser Internals
Search for a command to run...
No comments yet. Be the first to comment.
React is known for being fast and efficient when updating user interfaces. One of the main reasons behind this is the Virtual DOM and React's reconciliation process. But what actually happens when a c
Why We Need Modules In the early days of the web, scripts were loaded one after another. This led to several "code organization nightmares": Global Namespace Pollution: Variables from one file would
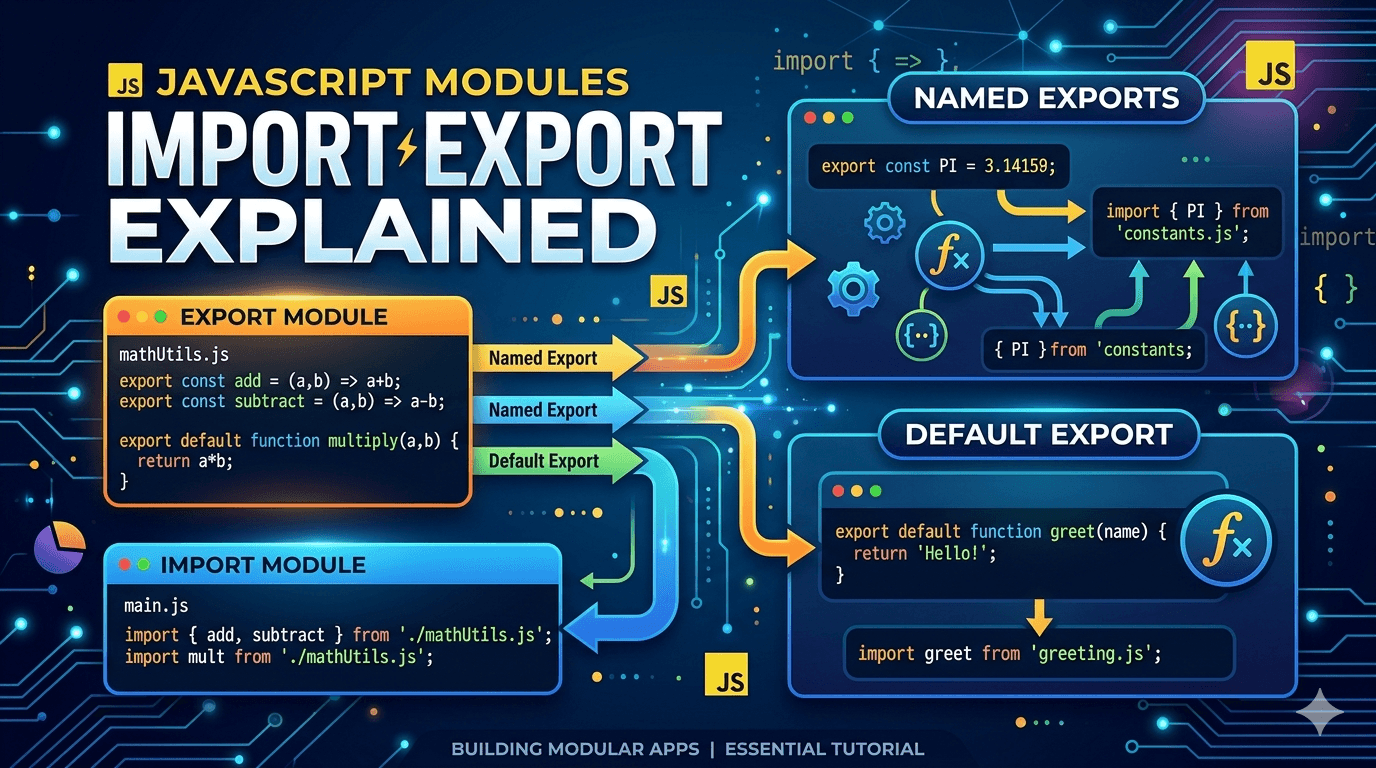
This guide explores the transition from traditional callback patterns to modern Promise-based execution in Node.js, highlighting why asynchronous patterns are the heart of the platform. 1. Why Async
Modern JavaScript introduced arrow functions in ECMAScript 2015 to reduce boilerplate and make functions shorter and easier to read. Arrow functions use the => syntax and provide a concise way to writ

Variables — Containers for Storing Data A variable is a container where you can store data. In JavaScript, there are 3 ways to declare variables: • var — Old method, function-scoped, can be overwritte

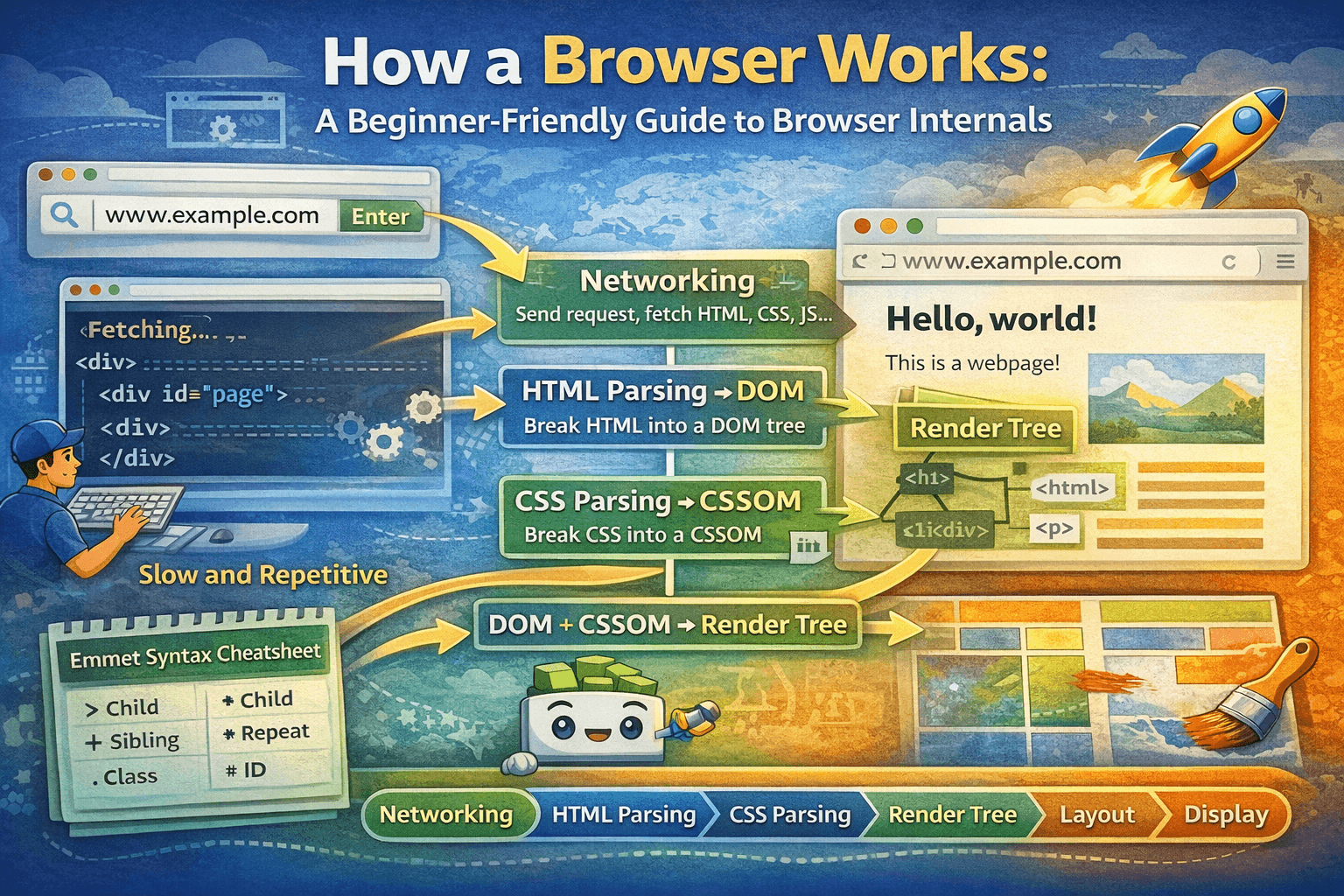
A web browser is software that fetches content from the internet and displays it to you as interactive web pages. It does much more than just open links — it processes, parses, layouts, and renders content like HTML, CSS, and JavaScript to show complete pages. As such, a browser acts as an HTTP client or user agent that requests and processes data from servers.
Behind the scenes, a browser is a collection of coordinated components — ranging from the user interface you interact with, to internal engines that interpret and display content.
A typical browser consists of the following major parts:
This is what you see and interact with:
Address bar
Tabs
Back/forward buttons
Bookmarks
Window controls
These are all UI elements that make the browser usable, but not involved in actual page processing.
This is the core that turns downloaded content into what you see:
Browser engine: The control center that coordinates between UI and rendering.
Rendering engine: Parses HTML and CSS; builds internal structures and renders the page visually. Different browsers use different engines (for example, Chrome uses Blink, Firefox uses Gecko).
This component handles communication over the internet. When you hit Enter:
Browser obtains the URL you typed.
It resolves the host via DNS and establishes a network connection.
It sends an appropriate HTTP request to the server.
It receives raw response data — usually HTML, CSS, JavaScript, and assets (images, videos).
Once raw bytes of HTML are received, the browser:
Converts raw bytes into text.
Parses HTML into tokens and builds a tree structure called the Document Object Model (DOM).
Each HTML element becomes a node in this tree, representing the structure of the page.
Separately, CSS files and style blocks are parsed and combined into the CSS Object Model (CSSOM) — another tree structure describing how elements should look (styles, selectors, properties).
After both DOM and CSSOM are ready:
The browser combines them into a Render Tree.
The Render Tree contains only the elements that will actually be displayed on the page — invisible elements (like those with display: none) are excluded.
With the Render Tree constructed:
The browser computes exact sizes, positions, and geometry for every element.
This step determines where everything goes on the screen — it’s called layout or reflow.
Finally:
The browser paints visual elements — filling in pixels, colors, text, images, borders, shadows, etc.
Depending on the browser’s architecture, this might be done in layers and composed into the final screen output.
This entire pipeline — from receiving HTML bytes to displaying pixels — happens very quickly, usually in milliseconds.
Parsing is similar to understanding a sentence:
Raw text: "<h1>Hello</h1>"
Parser reads characters → recognizes tags → builds a structured representation (DOM tree).
This structured interpretation helps the browser know “what’s where” before it lays things out.
Here’s the simplified flow from URL to screen:
User enters URL and presses Enter.
Browser sends a network request and gets HTML, CSS, JS.
HTML is parsed → DOM tree created.
CSS is parsed → CSSOM created.
DOM + CSSOM → Render Tree (visible structure + style).
Layout (Reflow) calculates positions & dimensions.
Paint draws pixels to the screen.