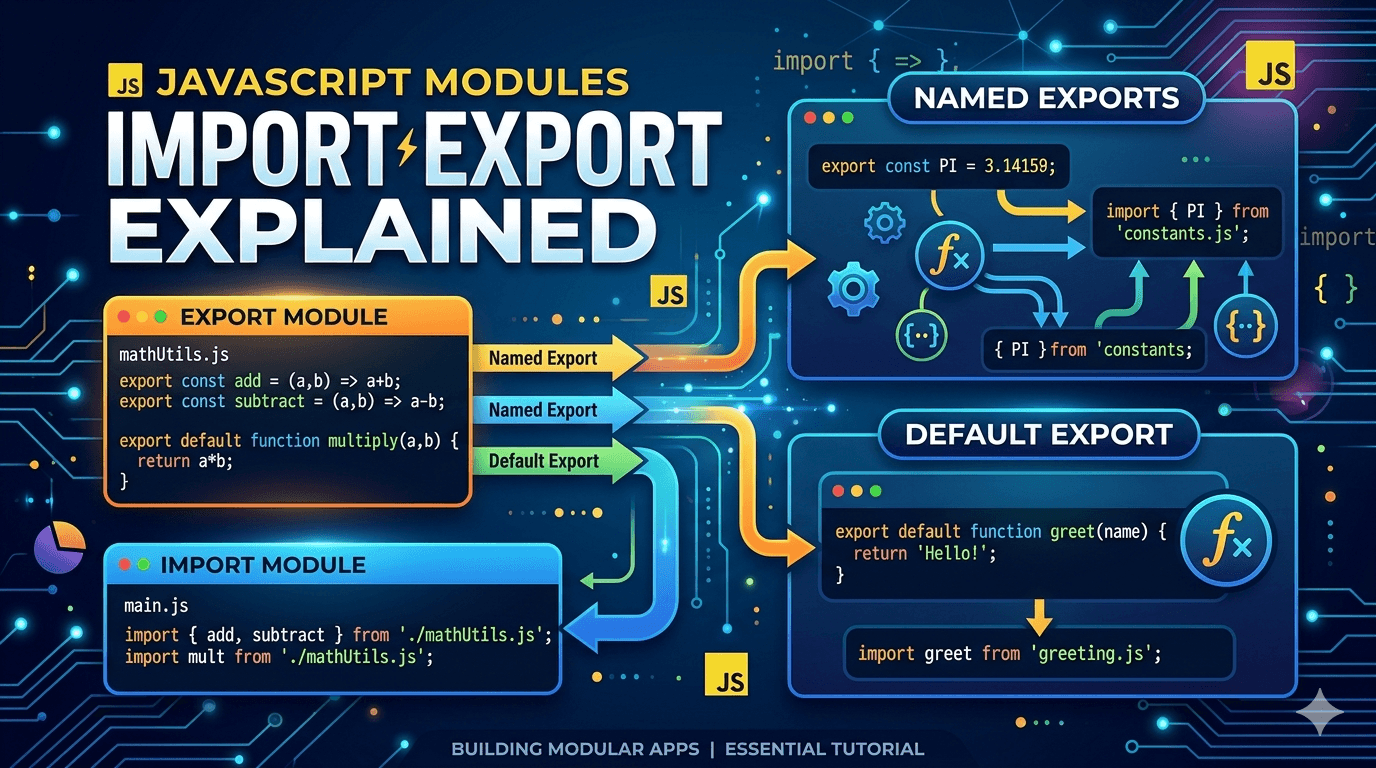
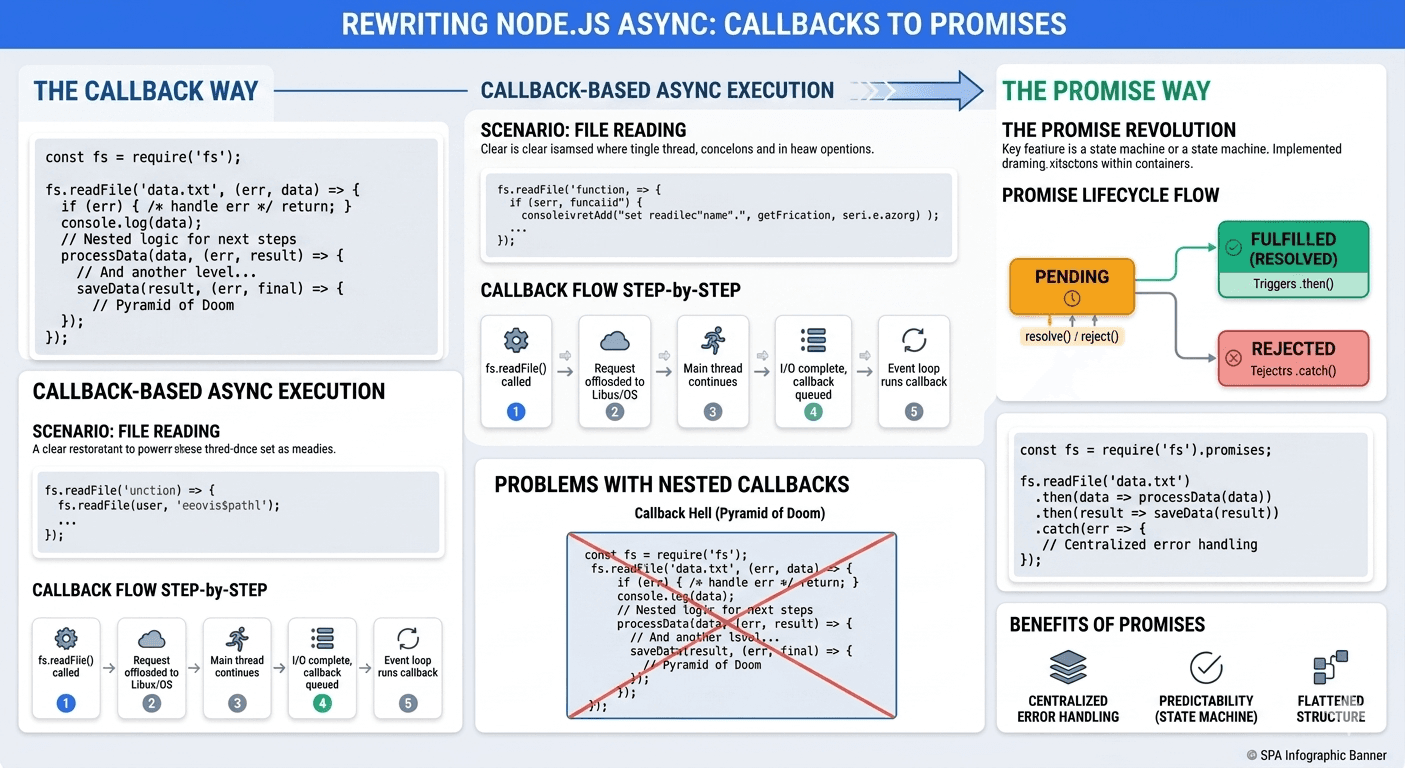
How DNS Resolution Works
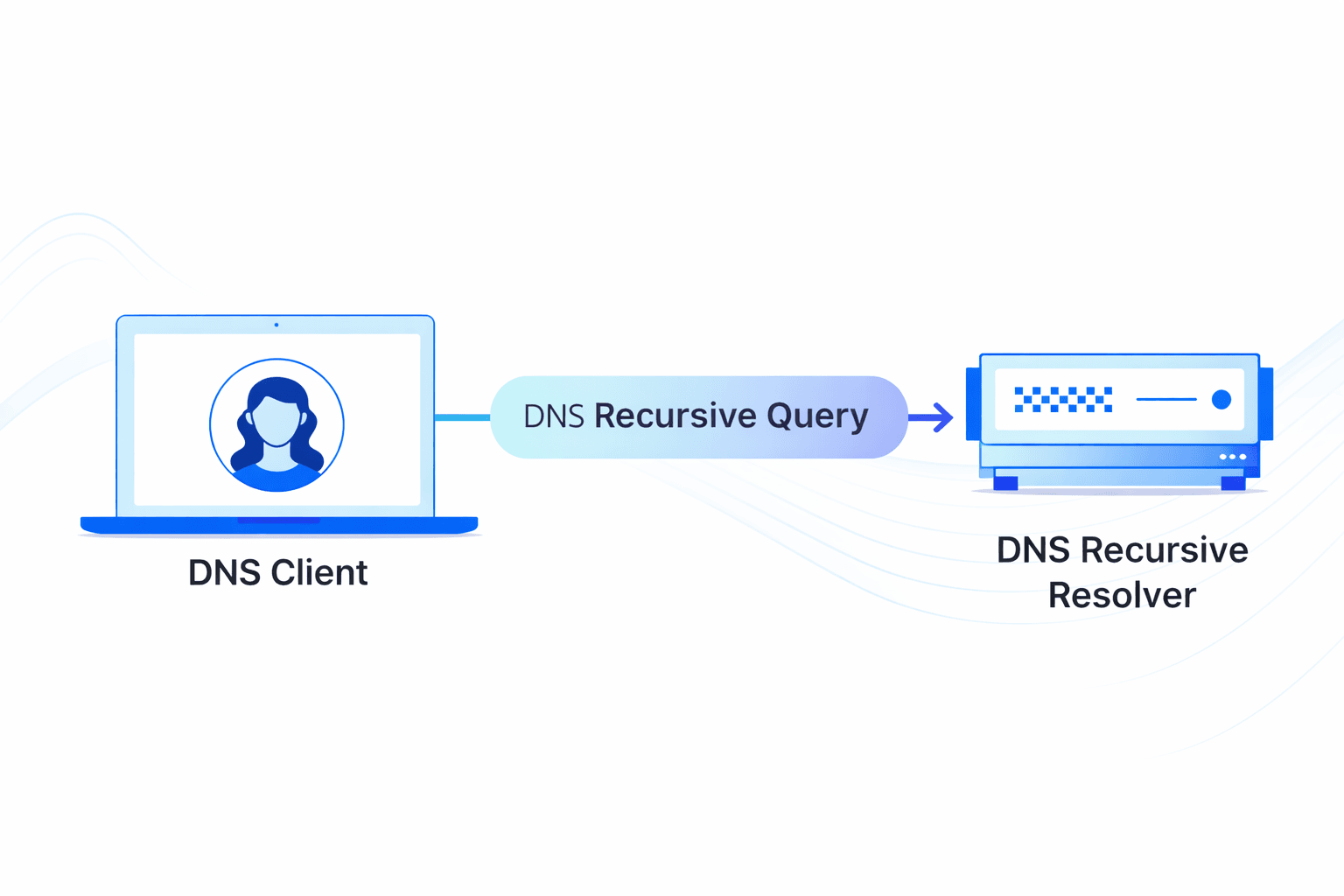
The DNS resolver is the first stop in the DNS lookup, and it is responsible for dealing with the client that made the initial request. The resolver starts the sequence of queries that ultimately leads to a URL being translated into the necessary IP address.
Note: A typical uncached DNS lookup will involve both recursive and iterative queries.
It's important to differentiate between a recursive DNS query and a recursive DNS resolver. The query refers to the request made to a DNS resolver requiring the resolution of the query. A DNS recursive resolver is the computer that accepts a recursive query and processes the response by making the necessary requests.
What are the types of DNS queries?
In a typical DNS lookup three types of queries occur. By using a combination of these queries, an optimized process for DNS resolution can result in a reduction of distance traveled. In an ideal situation cached record data will be available, allowing a DNS name server to return a non-recursive query.
3 types of DNS queries:
Recursive query - In a recursive query, a DNS client requires that a DNS server (typically a DNS recursive resolver) will respond to the client with either the requested resource record or an error message if the resolver can't find the record.
Iterative query - in this situation the DNS client will allow a DNS server to return the best answer it can. If the queried DNS server does not have a match for the query name, it will return a referral to a DNS server authoritative for a lower level of the domain namespace. The DNS client will then make a query to the referral address. This process continues with additional DNS servers down the query chain until either an error or timeout occurs.
Non-recursive query - typically this will occur when a DNS resolver client queries a DNS server for a record that it has access to either because it's authoritative for the record or the record exists inside of its cache. Typically, a DNS server will cache DNS records to prevent additional bandwidth consumption and load on upstream servers.
🌐 1. What is DNS? — The Internet’s Phonebook
The Domain Name System (DNS) translates human-friendly names like:
google.com
into machine-usable IP addresses like:
142.250.190.78
Without DNS, we’d have to memorize numerical IPs for every website — like remembering someone’s phone number instead of their name.
Think of DNS as the internet’s phonebook:
| Domain Name | IP Address |
google.com | 142.250.190.78 |
openai.com | 34.201.222.82 |
Your computer asks DNS “What’s the number for this name?” — and DNS gives back the IP.
🛠 2. Introducing dig — the DNS Diagnostic Tool
dig is a command-line utility used to query and troubleshoot DNS resolution.
It lets you see:
✔ What DNS records exist
✔ Which DNS server answered your query
✔ How long the answer is valid
✔ The path your query took through DNS infrastructure
By inspecting the output manually, you build a mental model of how DNS works under the hood.
🧱 3. How DNS Resolution Works — Layer by Layer
DNS resolution is hierarchical. A recursive resolver does the heavy lifting by navigating this stack:
Your Client
↓
Recursive Resolver
↓
Root Nameservers
↓
TLD Nameservers (e.g., .COM)
↓
Authoritative Nameservers
↑
Answer returned all the way back
Let’s break that down.
🌀 Root Nameservers
These are the top of the DNS hierarchy. They don’t know your final domain’s IP, but they know where to find the TLD servers.
🔤 TLD Nameservers
For .com, .org, .net, etc., these hold pointers to authoritative servers for your specific domain.
📁 Authoritative DNS
This is the final stop — the source of truth for a domain’s DNS records (A, NS, MX, TXT, etc.)
👣 4. Walkthrough: Understanding dig Outputs
Here’s what running certain dig commands tells you.
1. Basic lookup
dig google.com
This does:
Sends query to your default recursive resolver
Asks for the A record (IPv4) of google.com
Shows you the answer and details about the query
You’ll see sections like:
QUESTION SECTION — what was asked
ANSWER SECTION — what was returned
AUTHORITY SECTION — DNS servers that are authoritative
ADDITIONAL SECTION — extra info like IPs for nameservers
2. Query only NS records
dig google.com NS
This asks for NS (name server) records — essentially:
“Which servers are authoritative for this domain?”
Why NS records matter:
They tell resolvers who is responsible for answering about that domain
They guide the recursive resolver where to ask next
Example output snippet:
google.com. 86400 IN NS ns1.google.com.
google.com. 86400 IN NS ns2.google.com.
3. Asking a specific DNS server
dig @8.8.8.8 google.com
This:
Tells
digto query Google’s public DNS (8.8.8.8) instead of your default resolverHelpful to compare resolver behavior
🧠 5. What Are NS Records and Why They Matter
NS (Name Server) records list DNS servers authoritative for a domain.
They matter because:
✔ They tell the recursive resolver where to go next
✔ They distribute DNS responsibility across multiple servers
✔ They enable redundancy — if one NS is down, others answer
So when a resolver asks the root:
What is the A record for google.com?
The root says:
Ask these TLD .com servers → they know where google.com’s authoritative servers are.
Then the resolver goes to .com and asks:
Where are the NS for google.com?
And so on.
🔄 6. How Recursive Resolvers Use This
A recursive resolver (like your ISP DNS or 8.8.8.8) takes your query and does the entire journey through DNS hierarchy for you.
Recursive behavior:
Receive query from client
Check cache for an existing answer
If not cached, ask root → TLD → authoritative
Return final answer to client
Cache it for faster future responses
Clients don’t need to know about NS, TLD, or root servers — resolvers handle that.
🔗 7. Connecting dig google.com to Real Browser Requests
When you type a URL in your browser:
https://www.google.com
Your browser first needs an IP address for www.google.com.
So it:
Queries your recursive resolver (often provided by router/ISP)
Resolver returns
142.250.190.78Browser connects to that IP on port 443 (HTTPS)
TLS handshake and HTTP request happen next
In short:
Browser → DNS lookup (to get IP) → Connect to IP → Load web page
Without the DNS step, the browser wouldn’t know where to connect.
🧩 Summary
| Concept | Real-World Role |
| DNS | Internet phonebook |
| dig | Tool to inspect DNS answers |
| NS records | Tell you who’s authoritative |
| Recursive resolver | Does all lookup heavy lifting |
| Browser | Uses DNS answer to connect to a server |